멀티 레벨 큐 (Multilevel Queue)
이화여대 ‘반효경’교수님의 Operating Systems강의 중, ‘CPU Scheduling 2’강의를 수강하고 학습합니다.
Ready Queue를 여러 개의 큐로 나누어, foreground(인터랙티브 프로세스)와 background(배치 작업 - 인간과의 상호작용이 필요 없는 작업)로 분리합니다. 각 큐는 독립적인 스케줄링 알고리즘을 가질 수 있으며, 이는 다양한 작업의 특성을 반영하여 스케줄링을 효율적으로 수행하기 위한 방법입니다.
- Foreground: 라운드 로빈 (RR) 알고리즘 사용
- Background: FCFS (First-Come-First-Served) 알고리즘 사용
큐 간 스케줄링 방식
멀티 레벨 큐에서는 큐 자체에 대한 스케줄링도 필요합니다. 주요 방식은 다음과 같습니다.
고정 우선순위 스케줄링 (Fixed Priority Scheduling):
우선 foreground의 프로세스를 모두 처리한 후에 background 작업을 처리합니다.
하지만 우선순위가 낮은 background 작업이 계속 대기하는 기아 현상이 발생할 수 있습니다.타임 슬라이스 (Time Slice):
각 큐에 대해 CPU 시간을 적절히 할당하여, 여러 큐의 작업들이 공정하게 실행될 수 있도록 합니다.
멀티 레벨 피드백 큐 (Multilevel Feedback Queue)
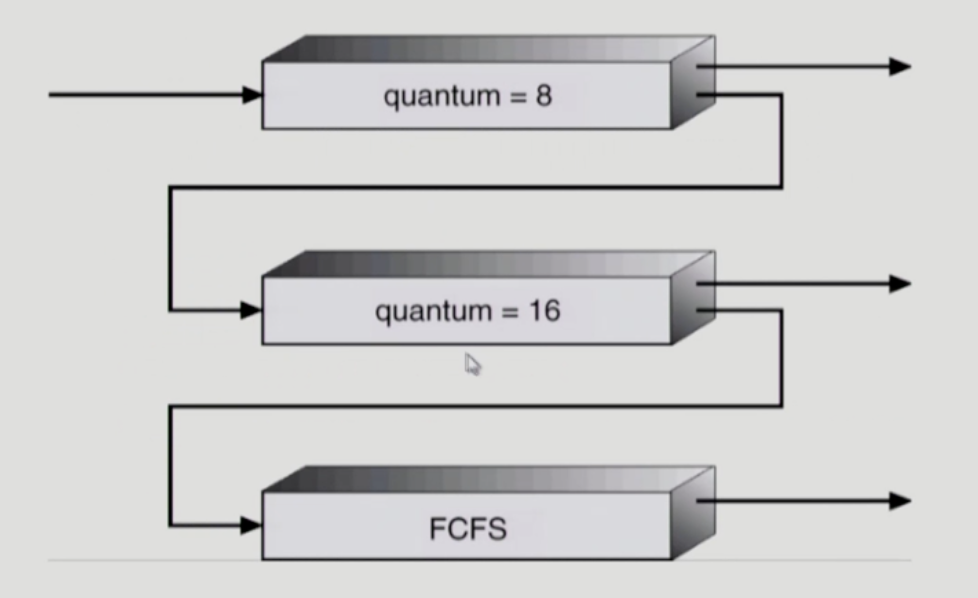
멀티 레벨 피드백 큐는 일반적인 멀티 레벨 큐와 달리 프로세스가 다른 큐로 이동할 수 있습니다. 예를 들어, 프로세스가 시간이 지남에 따라 우선순위가 변경되거나 다른 큐로 이동하는 방식으로 에이징 (Aging)을 구현할 수 있습니다.
- 상위 우선순위 큐에서 낮은 우선순위 큐로 프로세스가 이동하거나, 반대로 낮은 우선순위 큐에서 상위 우선순위 큐로 이동할 수 있습니다. 이는 기아 현상을 방지하고, 프로세스의 상태에 맞는 적절한 스케줄링을 수행할 수 있는 장점이 있습니다.
다중 프로세서 스케줄링 (Multiple-Processor Scheduling)
CPU가 여러 개 있는 경우, 스케줄링은 더 복잡해집니다.
동일한 프로세서 (Homogeneous Processor):
모든 프로세서가 동일하다면, 하나의 큐를 사용하여 프로세서들이 알아서 작업을 꺼내 가게 할 수 있습니다.
하지만 특정 프로세서에서만 실행되어야 하는 작업이 있으면, 상황은 더 복잡해집니다.부하 분산 (Load Sharing):
특정 프로세서에 작업이 몰리지 않도록 부하를 적절하게 분배하는 메커니즘이 필요합니다.
공동 큐를 사용할지, 아니면 별도의 큐를 둘지에 대한 결정도 중요합니다.대칭형 멀티프로세싱 (SMP, Symmetric Multiprocessing):
각 프로세서가 자체적으로 스케줄링을 결정하는 방식입니다.비대칭형 멀티프로세싱 (Asymmetric Multiprocessing):
한 프로세서가 시스템 데이터의 접근과 공유를 관리하고, 나머지 프로세서들은 이 지시에 따르는 방식입니다.
실시간 스케줄링 (Real-Time Scheduling)
실시간 시스템에서는 특정 작업을 정해진 시간 내에 완료해야 하는 요구사항이 있습니다.
하드 실시간 시스템 (Hard Real-Time System):
반드시 정해진 시간 안에 작업이 완료되도록 보장해야 합니다.소프트 실시간 시스템 (Soft Real-Time System):
우선순위가 높은 작업들이 일반 작업보다 우선되지만, 반드시 시간 내에 완료되지 않아도 됩니다.
스레드 스케줄링 (Thread Scheduling)
스레드 레벨에서도 스케줄링이 이루어지며, 사용자 수준 스레드와 커널 수준 스레드에 따라 달라집니다.
로컬 스케줄링 (Local Scheduling):
사용자 레벨 스레드의 경우, 사용자 수준 스레드 라이브러리에서 어떤 스레드를 스케줄링할지 결정합니다.글로벌 스케줄링 (Global Scheduling):
커널 레벨 스레드의 경우, 커널의 단기 스케줄러가 스레드를 스케줄링합니다.
알고리즘 평가 (Algorithm Evaluation)
스케줄링 알고리즘의 성능을 평가하기 위해 다양한 방법이 사용됩니다.
큐잉 모델 (Queueing Models):
프로세스의 도착률(arrival rate)과 서비스 속도(service rate)를 확률 분포로 주어 성능 지표를 계산합니다.구현 및 측정 (Implementation & Measurement):
실제 시스템에 알고리즘을 구현하여 성능을 측정하고 비교합니다.모의 실험 (Simulation):
알고리즘을 시뮬레이션하여, 미리 기록된 작업(trace)을 입력으로 사용하여 성능을 분석합니다.
